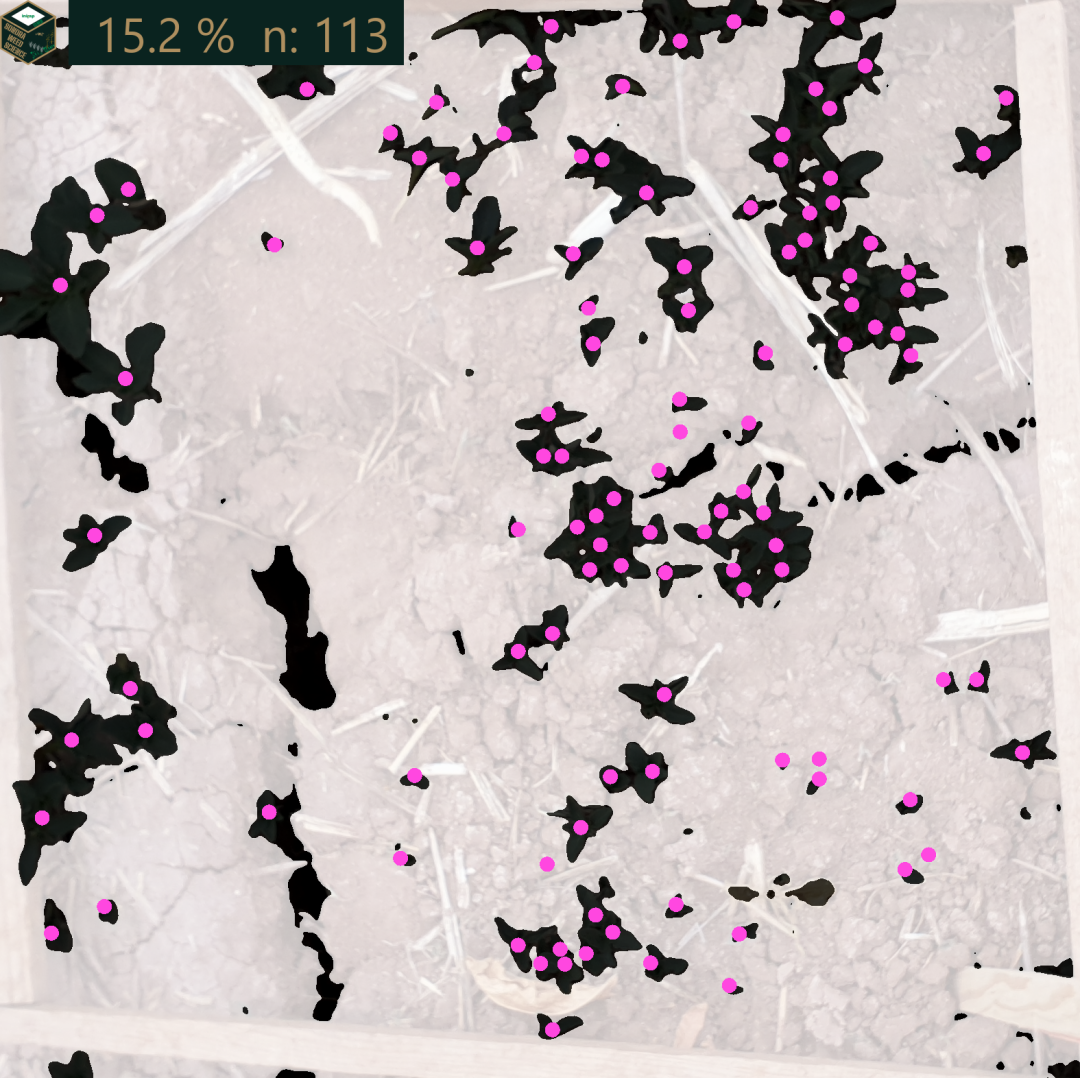
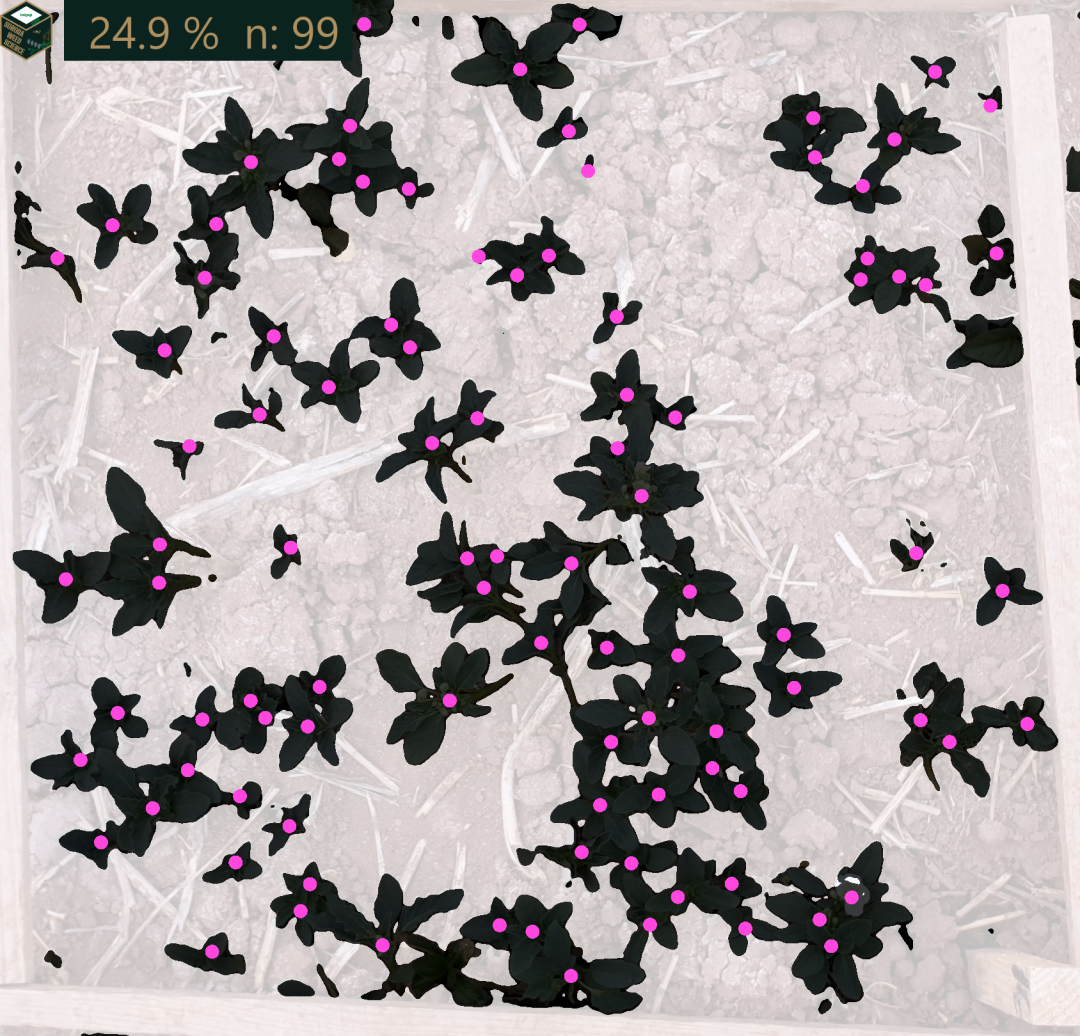
El siguiente codigo crea una función que genera una imagen en blanco y negro y calcula el porcentaje de cobertura de una imagen tomada en campo.
Código
library(imager)library(magick)library(dplyr)cobertura <-function(ruta, ruta_over, ruta_overlay, ruta_csv, nombre_imagen){image <-load.image(ruta)over <-image_read(ruta_over)overlay <-image_read(ruta_overlay)over2 <- over %>%image_composite(overlay, operator ="dissolve",compose_args ="25%",gravity="center")logo <-image_read("Images/SWS_Logo.png")R <-R(image); G<-G(image); B<-B(image)ExGreen<-2*G-R-B# blur before thresholding to fill some gapsExGreen <-isoblur(ExGreen, 3)ExGreen <-threshold(ExGreen, thr="auto", approx=FALSE, adjust=1)# Convertir la matriz en un vectorvector_image <-as.vector(ExGreen)negro <-as.numeric(summary(vector_image)['TRUE'])blanco <-as.numeric(summary(vector_image)['FALSE'])porcentaje_de_cobertura <-round((negro/(negro+blanco))*100,1)porCob <-paste("",porcentaje_de_cobertura, "%","")# Imagen en negativoExGreen2 <-print(plot(ExGreen))ExGreen3 <-image_read(ExGreen2)ExGreen4 <-image_negate(ExGreen3)ExGreen5 <-c(ExGreen4,over2, image_scale(logo, "95x95"))# Leer el archivo CSV con el conteo de plantasconteo <-read.csv(ruta_csv)# Obtener el número de plantas correspondiente a la imagen actualnumero_de_plantas <- conteo %>%filter(imagen == nombre_imagen) %>%select(tomatillo) %>%pull()# Convertir el número de plantas a textotexto_numero_plantas <-paste("n:", numero_de_plantas, "")muchotexto <-paste("",porCob, texto_numero_plantas)# Customnize textPC <-image_annotate(ExGreen5, muchotexto,size =70, color ="#ae8f5fff",boxcolor ="#0a231fff",degrees =0,location ="+100+000",font ='helvetica') resultado <-image_mosaic(PC) %>%image_scale("1080x")return(resultado)}cobertura_carpeta <-function(imagenes, resultados, ruta_csv) {# Obtener la lista de archivos en la carpeta de entrada archivos <-list.files(imagenes, full.names =TRUE)# Carpeta de salida para los resultados carpeta_salida <- resultados# Iterar sobre cada archivofor (archivo in archivos) {# Obtener el nombre del archivo sin la ruta nombre_archivo <-basename(archivo)# Obtener el nombre base de la imagen (sin extensión ni ruta) nombre_base <- tools::file_path_sans_ext(nombre_archivo)# Crear la ruta al overlay basada en el nombre de la imagen ruta_over <-file.path("images", "over", paste0(nombre_base, "_over.png")) ruta_overlay <-file.path("images", "overlay", paste0(nombre_base, ".png"))# Obtener el número de plantas correspondiente a la imagen actual conteo <-read.csv(ruta_csv) numero_de_plantas <- conteo %>%filter(imagen == nombre_archivo) %>%select(tomatillo) %>%pull()# Aplicar la función cobertura al archivo actual resultado <-cobertura(archivo, ruta_over, ruta_overlay, ruta_csv, nombre_archivo) # Ajusta los parámetros según tu función# Especificar el nombre del archivo de salida con el valor de porcentaje_de_cobertura nombre_salida <-paste0(sub(".jpg", "_procesada.jpg", nombre_archivo))# Especificar la ruta y nombre del archivo de salida en la carpeta de resultados ruta_de_salida <-file.path(carpeta_salida, nombre_salida)# Guardar la imagen procesada en la carpeta de salidaimage_write(resultado, path = ruta_de_salida) }}cobertura_carpetaNoOver <-function (imagenes, resultados){# Obtener la lista de archivos en la carpeta de entradaarchivos <-list.files(imagenes, full.names =TRUE)# Carpeta de salida para los resultadoscarpeta_salida <- resultados# Iterar sobre cada archivofor (archivo in archivos) {# Obtener el nombre del archivo sin la ruta nombre_archivo <-basename(archivo)# Aplicar la función cobertura al archivo actual resultado <-cobertura(archivo)# Modificar el nombre del archivo de salida con el valor de porcentaje_de_cobertura nombre_salida <-paste0(sub(".jpg", "_procesada.jpg", nombre_archivo))# Especificar la ruta y nombre del archivo de salida en la carpeta de resultados ruta_de_salida <-paste0(carpeta_salida, nombre_salida)# Guardar la imagen procesada en la carpeta de salidaimage_write(resultado, path = ruta_de_salida) }}#cobertura_carpeta("images/ImageR/", "images/resultados2/", "pcounts.csv")
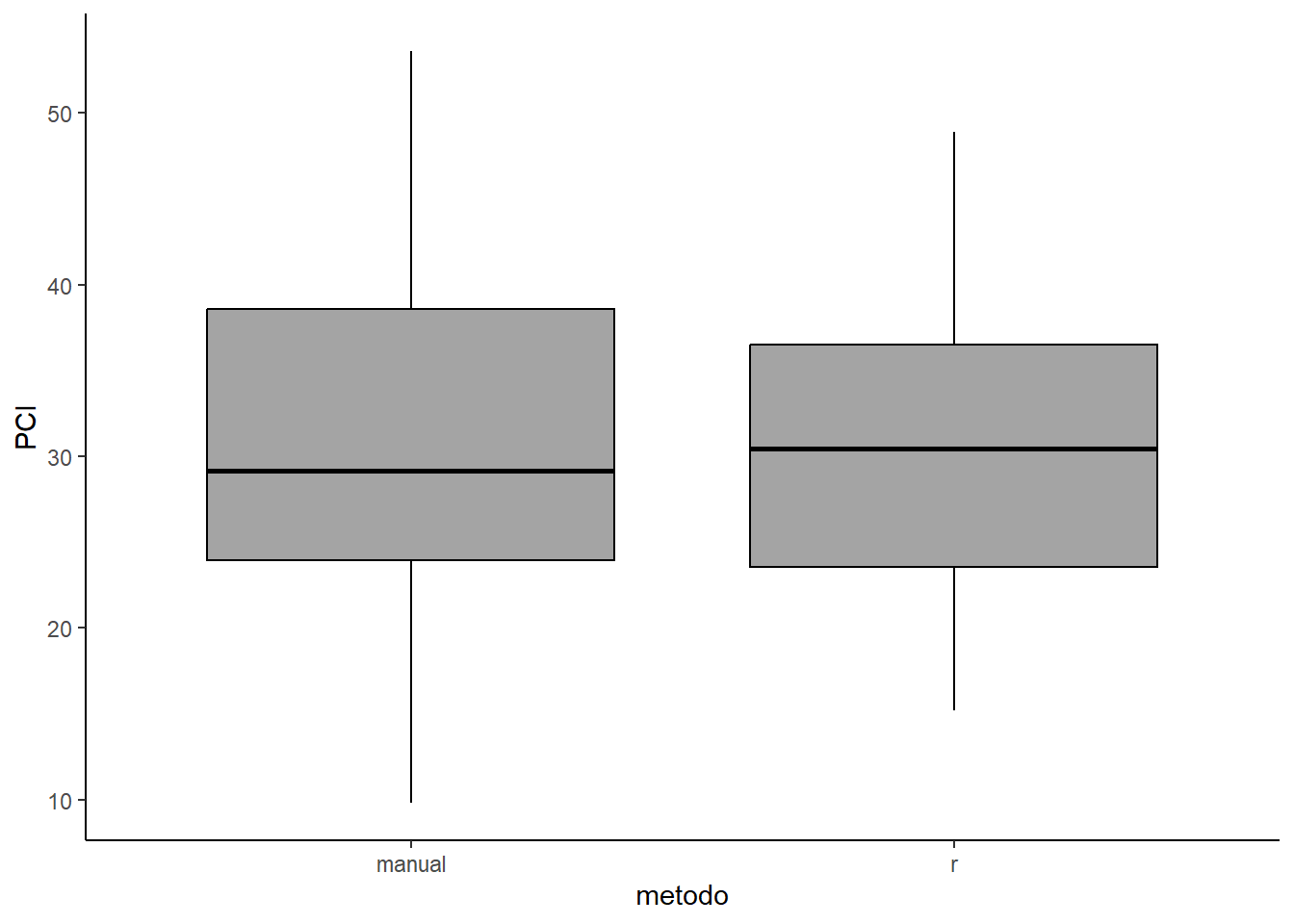
Wilcoxon rank sum test with continuity correction
data: PCI by metodo
W = 74, p-value = 0.931
alternative hypothesis: true location shift is not equal to 0
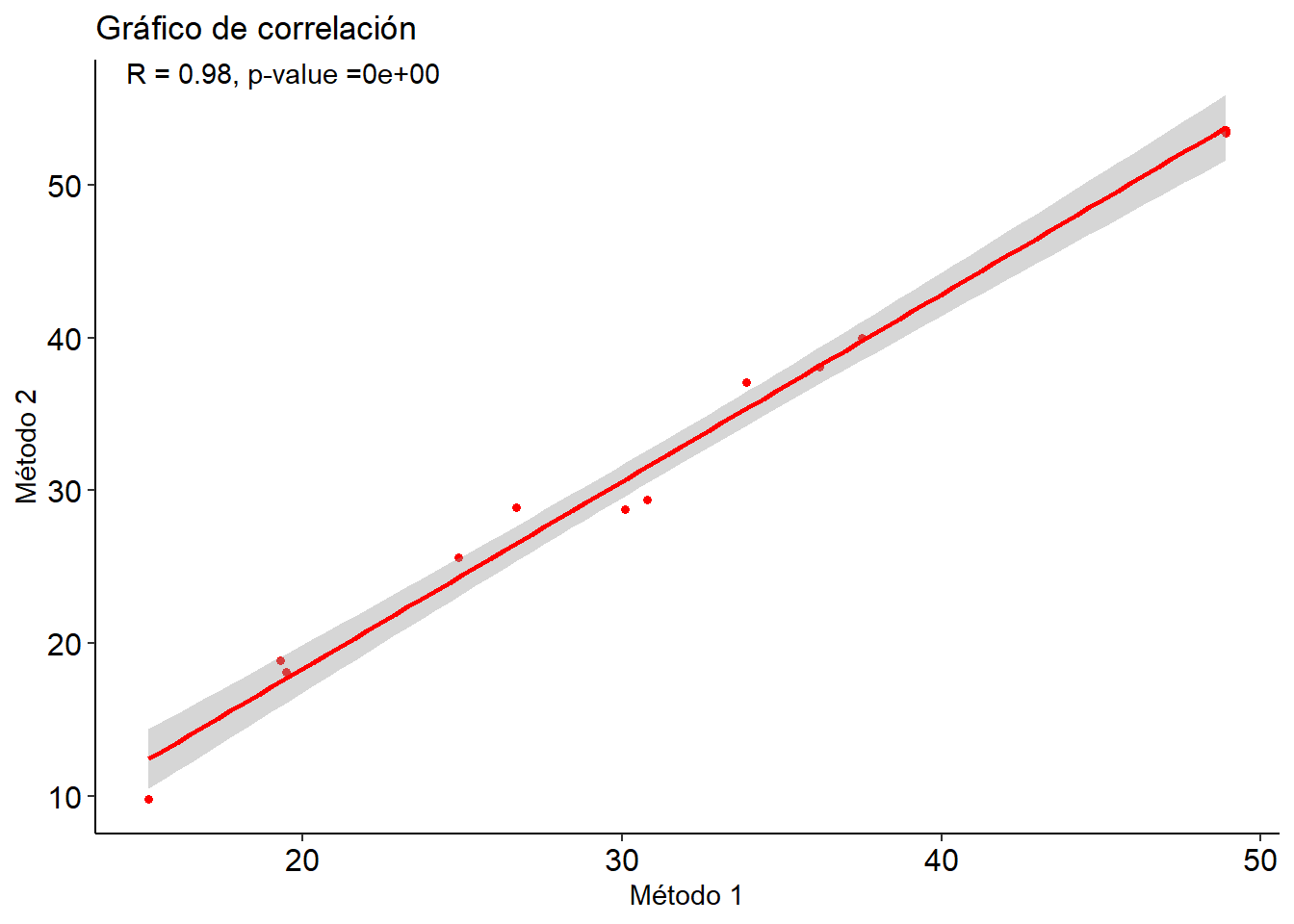
Código
test2 <-t.test(PCI ~ metodo, tabla)print(test2)
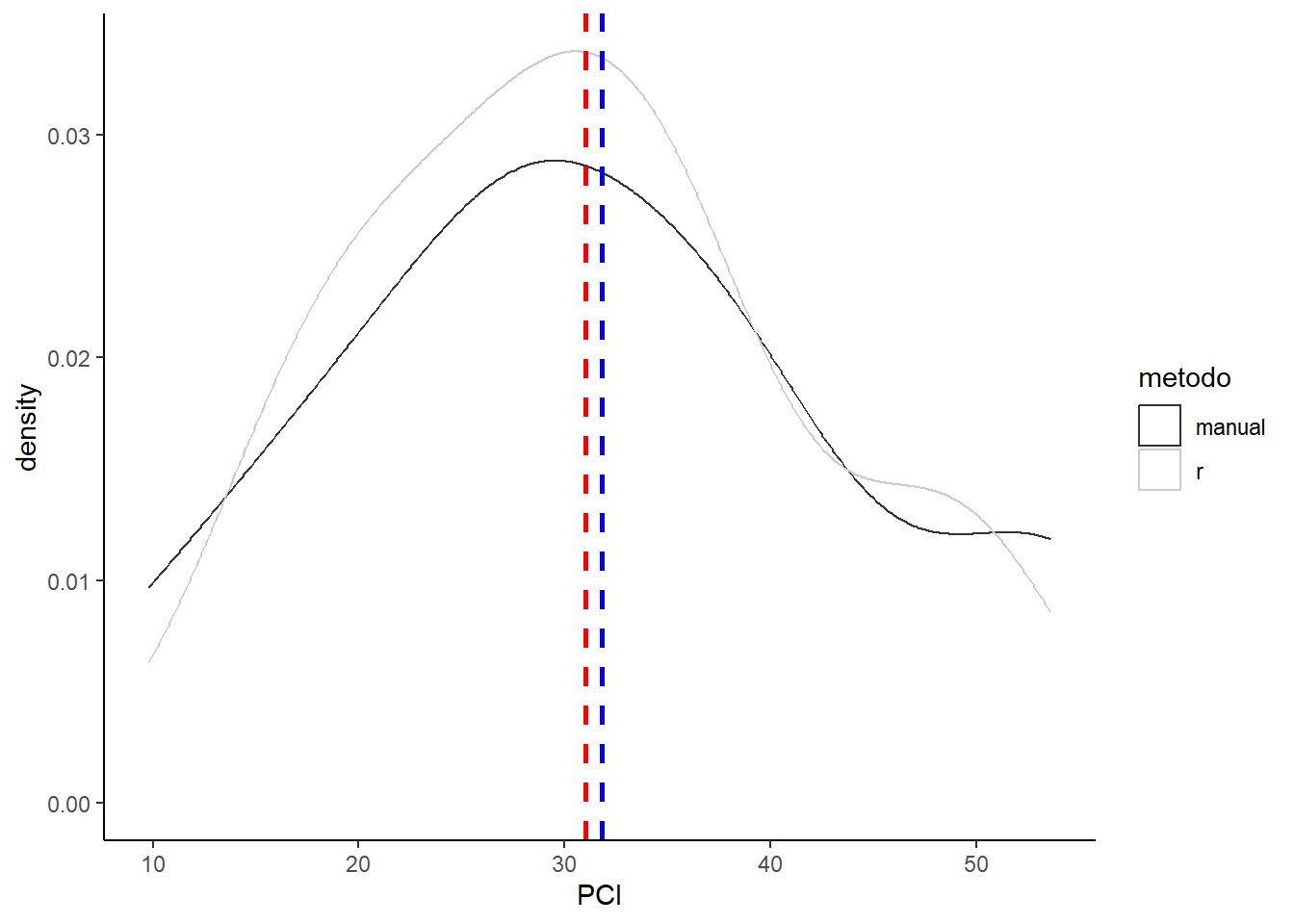
Welch Two Sample t-test
data: PCI by metodo
t = 0.16407, df = 21.081, p-value = 0.8712
alternative hypothesis: true difference in means between group manual and group r is not equal to 0
95 percent confidence interval:
-9.532197 11.165530
sample estimates:
mean in group manual mean in group r
31.80833 30.99167